
If you’re intrigued by the concept of AI assistants like ChatGPT, Google Bard, Bing Chat, or others, you might have certain apprehensions regarding privacy, expenses, and beyond. This is where Llama 2 steps in.
LLaMA (Language Model for Answering) is a powerful language model developed by Facebook that can understand and respond to natural language input in a conversational manner. It is the successor of the original LLaMA model, which was released in 2019.
LLaMA 2 builds upon the advancements made in the first version of the model, with several improvements in areas such as:
- Contextual Understanding: LLaMA 2 has improved contextual understanding abilities, enabling it to better comprehend the nuances of language and provide more accurate responses.
- Conversational Ability: The new model has been trained on a larger dataset and can engage in longer, more complex conversations than its predecessor.
- Emotional Intelligence: LLaMA 2 has been fine-tuned to recognize and respond to emotions expressed in text, such as empathy or sarcasm.
- Multi-Turn Responses: The model can now engage in multi-turn conversations, where it responds to multiple messages in a conversation without losing context.
- Improved Performance: LLaMA 2 has been optimized for better performance on a wide range of tasks, including question answering, text classification, and language translation.
Overall, LLaMA 2 represents a significant improvement over the original LLaMA model, with enhanced conversational abilities, emotional intelligence, and multi-turn response capabilities.
This model is trained on 2 trillion tokens, and by default supports a context length of 4096. Llama 2 Chat models are fine-tuned on over 1 million human annotations, and are made for chat.
Some use cases for software developers
- Explain what this code does
- Simplify it
- Rewrite it in a more efficient way
- Rewrite it in a more readable way
- Replace the use of a library with another
- Write documentation for it
- Describe potential edge cases
- Write unit tests for those edge cases
Memory requirements
- 7b models generally require at least 8GB of RAM, 3.8GB download
- 13b models generally require at least 16GB of RAM, 8GB download
- 70b models generally require at least 64GB of RAM If you run into issues with higher quantization levels, try using the q4 model or shut down any other programs that are using a lot of memory.
How to run Llama 2 on your Mac, Linux or Windows for free using Ollama
If you have a Mac or Linux (Windows support coming), you can use Ollama to run LLaMA 2. It’s by far the easiest way to do it of all the platforms, as it requires minimal work to do so. All you need is a Mac and time to download the LLM, as it’s a large file.
Download Ollama
The first thing you’ll need to do is download Ollama . It runs on Mac and Linux and makes it easy to download and run multiple models, including Llama 2. Once Ollama is downloaded, move the ollama.app to the MacOS application folder and run it.
If you have 8GB RAM
info
LLMA3 is now available, use below instead ``ollama run llama3`
We will then download a 7billion parameter LLaMA 2 model. Open a new Terminal and run (it will download a bit less than 4GB)
ollama run llama2
If you have 16GB RAM
We will then download a 13billion parameter LLaMA 2 model. Open a new Terminal and run (it will download a bit less than 8GB)
ollama pull llama2:13b
then run it with
ollama run llama2:13b
You’re4 done, you have a chat gpt like ai assisant in your terminal for free!
Running Ollama in a web browser
We will use docker compose
version: '3.8'
services:
ollama:
volumes:
- ollama:/root/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
image: ollama/ollama:latest
ollama-webui:
build:
context: .
args:
OLLAMA_API_BASE_URL: '/ollama/api'
dockerfile: Dockerfile
image: ghcr.io/ollama-webui/ollama-webui:main
container_name: ollama-webui
volumes:
- ollama-webui:/app/backend/data
depends_on:
- ollama
ports:
- ${OLLAMA_WEBUI_PORT-3003}:8080
environment:
- 'OLLAMA_API_BASE_URL=http://ollama:11434/api'
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
ollama: {}
ollama-webui: {}
you can now access http://localhost:3003 and self register an admin account
Using text-generation-webui user interface for nearly any AI model
We will be using the project https://github.com/oobabooga/text-generation-webui
warning
Most serious and performing model need a beefy graphic card and lot of memory, dont expect to run them on a low or mid range GPU or older CPU
git clone https://github.com/oobabooga/text-generation-webui
then start either one of these scripts in a terminal
- start_linux.sh
- start_windows.bat
- start_macos.sh
- start_wsl.bat
now browse to http://127.0.0.1:7860
Go to the model tab, we need to load LLama 2 with 13Billion parameters first
go to Download model or LoRA and use TheBloke/Llama-2-13B-Chat-fp16 (32GB of download)
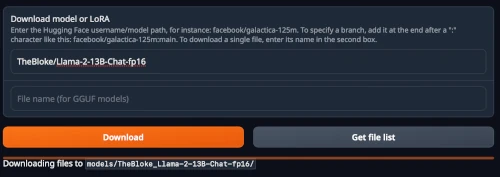
Click the download button and wait….
When finished, hit the reload button, select the model in the list box, and you’re done

{kind=link}